I'm sure some of you have read this story (or in French) about using dictionary attacks to figure out what the blacked out text is in partially declassified documents. To explain it in simple terms, since you know how long the hidden word or phrase is, you can vastly reduce the possibilities and make an educated guess as to what is hidden.

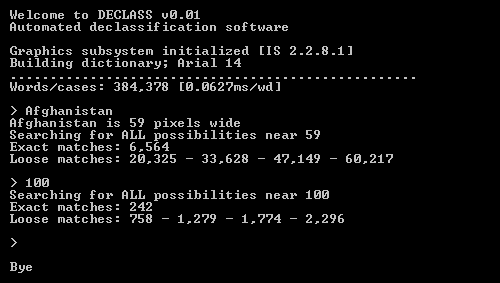
My automated rhyming dictionary is built around a word database that understands whether a word is a noun, a verb, or whatever, as well as tense… I think adding this could tune the output even more, and I'm pretty sure that in a lot of these documents, once you get a few of the censored bits, the rest start falling into place — so you have to find the single word ones, and then prioritize those in your dictionary and attempt to build the phrases around those — and a lot of the time you already have a short-list of potential words (ie. in the document above, you can short-list the names of all the suspects). Et cetera. If you get this entry in general, I'm sure you're understanding just how simple this is!
Does anyone know if it's illegal to release something like this?



Post a Comment